In CATALYST Professional, Object Analyst is an object-based image-analysis (OBIA) classification. It is used to segment an image into objects for classification and analysis. It differs from the traditional pixel-based approach, which focuses on a single pixel as the source of analysis.
Object Analyst algorithms can be run using the CATALYST Python API. These algorithms allow users to easily run an object-based classification on many datasets.
The CATALYST Professional Object Analyst workflow has a batch classification feature. By using batch classification, you can run classification simultaneously on a collection of images with similar qualities of acquisition. The collection can be any aerial, satellite, or SAR imagery you want classify similarly, such as, but not limited to, airphotos (strips or individual images), stacks of historical imagery, overlapping images, or contiguous images.
First, run a classification on an individual image that you want to use as reference image for the batch you want to process. Once the classification results from that image are deemed acceptable, then run a batch classification on the rest of the images to apply the same classification to each. The batch classification applies the following steps:
More information on each of the steps that are run in this tutorial is included in the online Help Documentation for CATALYST Professional.
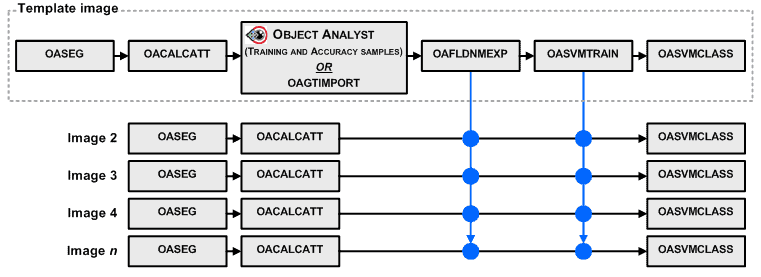
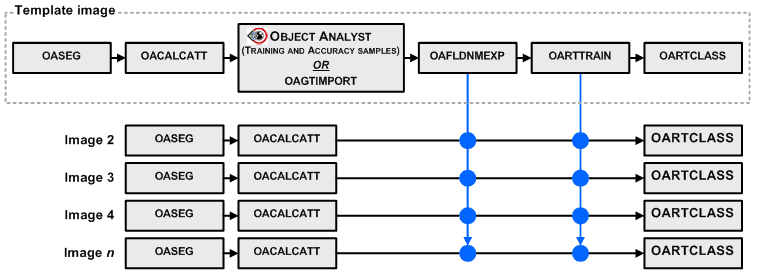
Each of the additional images is processed in a batch Python (for this tutorial, v3.5) script, using the attribute field name text file and training model that were generated from the initial image. The diagrams below show the basic training and classification workflows for a Support Vector Machine (SVM) and a Random Tree (RT) classification.
For this tutorial, multi-temporal Landsat-8 data is used, acquired in June over four different years:
The tutorial data and script can be downloaded.
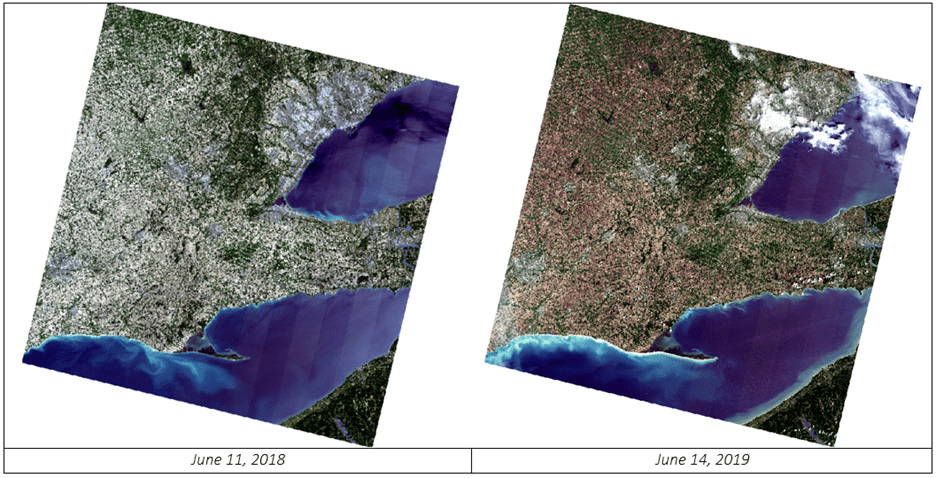
The figures below show the datasets. Notice that two of the batch images include clouds while the initial image does not.
This factor will be part of the classification exercise. The clouds in those images will be incorrectly classified initially, as there was no cloud class in the initial image classification. After running batch classification, we will run rule-based classification on the two images with cloud to create a new cloud class.
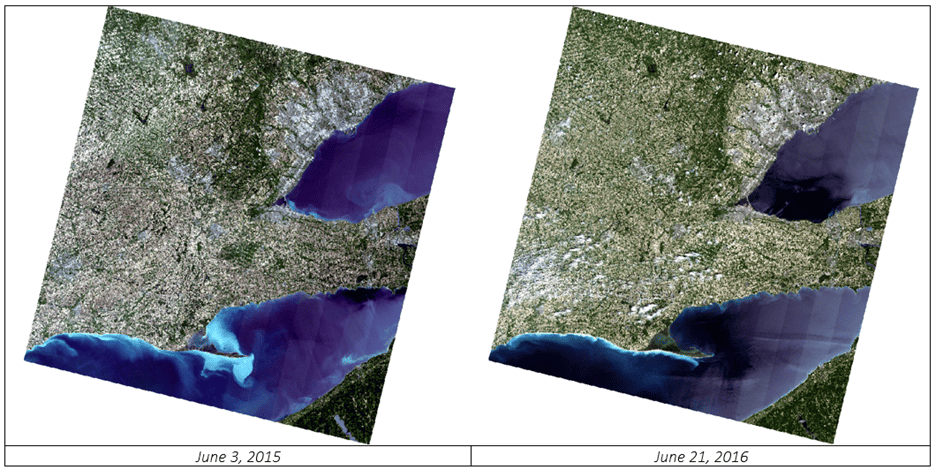
The first step is to process the initial image. In this case we will use: LC08_L1TP_018030_20150603_20170226_01_T1 (June 3, 2015) as the initial image.
The following algorithms will be run on the initial image to generate the training model and complete the classification:
You can check the CATALYST Professional Help documentation for additional information on the required parameters for each algorithm.
The first step in the Python script is to import the required modules and set up the variables that will point to our input and output directories and files. You can import the following modules:
Create input and output variables as outlined below.
# ---------------------# --------------------- |
The OASEG algorithm applies a hierarchical region-growing segmentation to image data and writes the resulting objects to a vector layer. The input file (fili) is the initial image variable (init_image) that we defined above. The output image will be the new segmentation file (init_seg). The scale parameter (segscale) will be set to 35 – this will create larger segments then the default of 25.
|

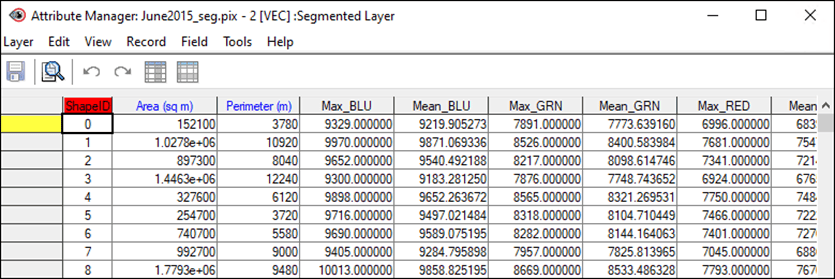
The OACALCATT algorithm calculates attributes of objects (polygons) in a vector layer, and then writes the output values to the same or a new segmentation vector layer.
The input image (fili) will be set to the initial image (image) that is being processed in the loop. Only channels 2-6 (B, G, R, NIR, SWIR) and 8 (Cirrus clouds) will be used in the attribute calculation (dbic). These attributes are calculated for each of the polygons in the segmentation layer created in OASEG (filv, dbvs). The calculated attributes are then saved back to the same segmentation layer (filo, dbov). The Maximum and Mean statistical attributes (statatt) and Rectangularity geometrical attribute (geoatt) will be calculated. Additionally, NDVI vegetation index will be calculated (index) which will help to classify vegetation.
|
The OAGTIMPORT algorithm will import a series of training or accuracy sample points into the attribute table of a segmentation file. The training or accuracy samples must be vector points (not polygons) with a field containing the class names. In this example, the ground truth dataset includes points that were collected from the initial image in Focus. You may have existing ground truth points for your own datasets.
Note: To convert existing training site or classification data from polygons to points, use the POLY2PNT algorithm.
|
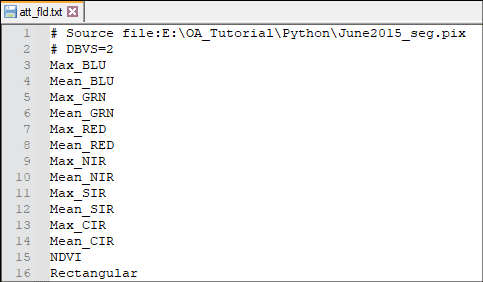
The OAFLDNMEXP algorithm exports the names of attribute fields from an OA segmentation file to a text file.
|
The OASVMTRAIN algorithm uses a set of training samples and object attributes, stored in a segmentation attribute table, to create a series of hyperplanes, and then writes them to an output file containing a Support Vector Machine (SVM) training model.
|
The OASVMCLASS algorithm uses the SVM method to run a supervised classification based on an SVM training model you specify. This is the final algorithm that needs to be run on the initial image in order to complete the classification. When this algorithm is run, new fields are added to the output file (filo) which include the classification information.
|
Similar to the SVM classification algorithms you can specify the Random Trees (RT) classification algorithms, OARTTRAIN and OARTCLASS, instead. RT belongs to a class of machine learning algorithms which does ensemble classification. The classifier uses a set of object samples that are stored in a segmentation-attribute table. The attributes are used to develop a predictive model by creating a set of random decision-trees and by taking the majority vote for the predicted class.
You can choose to run the SVM algorithms or the RT algorithms. Below is code for RT algorithms.
|
Note: See bottom of Section 2 for full Python script.
Now that the initial image is classified, we can apply that same training model to the additional images.
The first step is to create a list of all valid additional images in the add_images folder. The glob module can be used to create a list of all .pix files in the add_images folder.
Using a for loop, iterate through the file_list. The algorithms within the loop will be run on each individual image. A new segmentation pix file (add_seg) will need to be created for each input image. The os module is used to establish the naming for the new segmentation file. The elements of the for loop are described below:

As before, the OASEG algorithm applies a hierarchical region-growing segmentation to image data and writes the resulting objects to a vector layer.
This time, the input image (fili) will be the current image (image) that is being processed in the loop. The output image will be the new segmentation file (add_seg). The scale parameter (segscale) will once again be set to 35 to create larger segments then the default.
As before, the OACALCATT algorithm calculates attributes of objects (polygons) in a vector layer, and then writes the output values to the same or a new segmentation vector layer.
The input image (fili) will be set to the current image (image) that is being processed in the loop. All other parameters and outputs are the same as for the initial attribute calculation.
If you ran an SVM classification on the original image, we will now run the OASVMCLASS classification in a similar method to how we ran it on the initial image. The same training model and attribute field text file will be used from the initial call to OAFLDNMEXP. The current segmentation file (add_seg) will be used as both the input and output (filv/dbvs, filo/dbov).
If you ran an RT classification (OARTTRAIN and OARTCLASS) on the original image, you will use OARTCLASS for the additional images.
Once the batch processing is complete, each segmentation file will include the classification fields:
You can then open the vector files in Focus and apply a representation to view the classification.
Below is the Python script for Section 2.
# -----------------------------
# Processing additional images
# -----------------------------
for image in file_list:
print("Currently processing:", os.path.basename(image))
add_seg = os.path.join(output_folder, os.path.basename(os.path.splitext(image)[0]) +
'_seg.pix')
# OASEG (OASEGSAR) - Segment an image
print("OASEG: Segmenting Image")
algo.oaseg(fili=image, filo=add_seg, segscale=[35], segshape=[0.5], segcomp=[0.5])
# OACALCATT (OACALCATTSAR) - Calculate object attributes
print("OACALCATT: Calculating Attributes")
algo.oacalcatt(fili=image, dbic=[2,3,4,5,6], filv=add_seg, dbvs=[2], filo=add_seg,
dbov=[2], statatt="MAX, MEAN", geoatt="REC", index="NDVI")
# OASVMCLASS - Object-based SVM classifier
print("OASVMCLASS: Run Supervised Classification")
algo.oasvmclass(filv=add_seg, dbvs=[2], tfile=fld, trnmodel=training_model, filo=add_seg,
dbov=[2])The full Python script for the tutorial is provided below.
from pci import algo
import os
import glob
# ---------------------
# Input Variables
# ---------------------
# Initial Image - This image will be used to generate the training model
init_image = r"E:\OA_Tutorial\Batch\Initial_Image\June2015.pix"
# Initial segmentation containing the training sites
init_seg = r"E:\OA_Tutorial\Python\June2015_seg.pix"
# Ground truth point file
ground_truth = r"E:\OA_Tutorial\Batch\ground_points.pix"
# Additional Images - The batch classification will be run on these images
add_images = r"E:\OA_Tutorial\Batch\Additional_Images"
# ---------------------
# Output Variables
# ---------------------
# Output file location
output_folder = r"E:\OA_Tutorial\Python"
# Text file containing exported attribute names
fld = r"E:\OA_Tutorial\Python\att_fld.txt"
# Training model
training_model = os.path.join(output_folder, "training_model.xml")
# ---------------------
# Segmentation - OASEG
# ---------------------
algo.oaseg(fili=init_image, filo=init_seg, segscale=[35], segshape=[0.5], segcomp=[0.5])
# ----------------------------------
# Attribute calculation - OACALCATT
# ----------------------------------
algo.oacalcatt(fili=init_image, dbic=[2, 3, 4, 5, 6, 8], filv=init_seg, dbvs=[2], filo=init_seg, dbov=[2], statatt="MAX, MEAN", geoatt="REC", index="NDVI")
# ------------------------------------
# Importing ground truth - OAGTIMPORT
# ------------------------------------
algo.oagtimport(gtfili=ground_truth, gtfldnme="gt_class", filv=init_seg, dbvs=[2],filo=init_seg, dbov=[2], samptype="Training", resrule="First")
# ----------------------------------------------------
# Exporting attribute fields to txt file - OAFLDNMEXP
# ----------------------------------------------------
algo.oafldnmexp(filv=init_seg, dbvs=[2], fldnmflt="ALL_OA", tfile=fld)
# -----------------------------------------
# Creating SVM training model - OASVMTRAIN
# -----------------------------------------
algo.oasvmtrain(filv=init_seg, dbvs=[2], trnfld="gt_class", tfile=fld, kernel="RBF", trnmodel=training_model)
# -----------------------------------------
# Running SVM classification - OASVMCLASS
# -----------------------------------------
algo.oasvmclass(filv=init_seg, dbvs=[2], tfile=fld, trnmodel=training_model, filo=init_seg, dbov=[2])
# -------------------------------------------------------------
# Creating and running RT classification - OARTTRAIN/OARTCLASS
# -------------------------------------------------------------
algo.oarttrain(filv=init_seg, dbvs=[2], trnfld="gt_class", tfile=fld, trnmodel=training_model)
algo.oartclass(filv=init_seg, dbvs=[2], trnmodel=training_model, filo=init_seg, dbov=[2])
# -----------------------------
# Processing additional images
# -----------------------------
for image in file_list:
print("Currently processing:", os.path.basename(image))
add_seg = os.path.join(output_folder, os.path.basename(os.path.splitext(image)[0]) +
'_seg.pix')
# OASEG (OASEGSAR) - Segment an image
print("OASEG: Segmenting Image")
algo.oaseg(fili=image, filo=add_seg, segscale=[35], segshape=[0.5], segcomp=[0.5])
# OACALCATT (OACALCATTSAR) - Calculate object attributes
print("OACALCATT: Calculating Attributes")
algo.oacalcatt(fili=image, dbic=[2,3,4,5,6], filv=add_seg, dbvs=[2], filo=add_seg,
dbov=[2], statatt="MAX, MEAN", geoatt="REC", index="NDVI")
# OASVMCLASS - Object-based SVM classifier
print("OASVMCLASS: Run Supervised Classification")
algo.oasvmclass(filv=add_seg, dbvs=[2], tfile=fld, trnmodel=training_model, filo=add_seg,
dbov=[2])
When a segmentation vector layer is loaded into Focus the classification will not be automatically shown. You will need to adjust the representation of the vector layer to show the classification. This representation can then be saved to a Representation Style Table (.RST) file and that RST file can be used to load the same representation for the additional vector layers.
To adjust the representation of the first segmentation vector file in Focus to display the classification results:
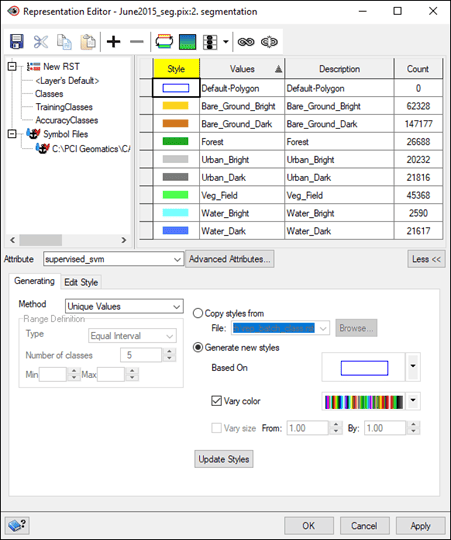
To be able to apply the same representation to other files, you will need to first save the representation to an RST (.RST) file.
To save the representation:

When you load the additional classifications to Focus you want to ensure that the RST file you created is linked to the map in your project. This representation can then be easily applied to the additional images.
To apply the RST to additional images: