The k-means nearest-neighbor (k-means) algorithm belongs to the partitioning clustering methods in which the mean value of the objects or observation in a cluster is used as a center of the cluster, which is also regarded as the center of gravity for a cluster. The k parameter is the total number of clusters to create.
The general approach for clustering with the k-means algorithm is regarded as an iterative-relocation technique. The objective of the algorithm is to improve the quality of the initial cluster. It implies that cluster membership is changed to find the local optima. The following is the general algorithm for iterative relocation:
Algorithm (Iterative Relocation): the generalized iterative-relocation algorithm
Input: The number of clusters k, and a database containing n objects
Output: A set of k clusters that minimize a criterion function E
- Arbitrarily choose k centers/distributions as the initial solution
- Repeat
- (Re)compute membership of objects according to present solution
- Update some or all cluster centers/distributions according to new memberships of the objects until (no change to E)
The clustering or object criterion (E) is to minimize the Euclidean sums of squared deviations of objects from the cluster mean, which is defined as follows:
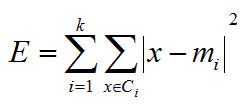
In the preceding formula, x is the point in space representing the given object and mi is the mean of the cluster (ci). In step 3 of the algorithm, k-means assigns each object to its nearest center forming a new set of clusters. All the centers of the new clusters are then computed by taking the means of all objects in each cluster. The process is repeated until the criterion function E does not change.